

Wie Algorithmus- und Embedded-Ingenieure effizienter zusammenarbeiten
Anleitung für einen modellbasierten Workflow für Motorregelungen auf SoC FPGAs

Wie Algorithmus- und Embedded-Ingenieure effizienter zusammenarbeiten
Anleitung für einen modellbasierten Workflow für Motorregelungen auf SoC FPGAs
Das Erstellen eines modellbasierten Workflows für Motorregelungen auf System-on-Chip FPGAs ist nicht ganz so einfach. Der hier vorgestellte modellbasierte Entwurf kann Algorithmus- und Embedded-Ingenieuren helfen, einen effizienten und kooperativen Entwurfsprozess zu schaffen.
Autor: Dr.-Ing. Werner Bachhuber, Mathworks
Für die Entwicklung und Verifikation von Regelalgorithmen wird überwiegend ein modellbasierter Entwurfsansatz eingesetzt. Dieser ermöglicht eine frühzeitige Simulation des Algorithmus zusammen mit dem physikalischen Modell der Regelstrecke. In diesem Artikel wird ein Workflow beschrieben, der darüber hinaus, durch Codegenerierung aus dem Simulationsmodell des Regelalgorithmus eine automatisierte Implementierung auf programmierbare System-on-Chip (SoC) FPGAs gestattet.
Verfeinerungsschritte auf Software und Hardware partitionieren
Die Modellierung hilft dabei, den Entwurf in weiteren Verfeinerungsschritten auf Software und Hardware zu partitionieren und die Funktionen auf die vorhandenen Implementierungsressourcen abzustimmen. Der Workflow erlaubt einerseits aus dem Simulationsmodell eine schnelle Prototypenimplementierung zu erreichen, andererseits kann nach dem Prototypentest im Labor ein produktionsreifer Implementierungscode generiert werden.
Heterogene, frei programmierbare System-on-Chips wie Xilinx Zynq SoCs, Intel SoC FPGAs und Microsemi SoC FPGAs, die programmierbare Logik und Mikroprozessorkerne auf dem gleichen Chip vereinen, bieten den Entwurfsteams neue Plattformen für die Algorithmenentwicklung in vielfältigen Anwendungsbereichen wie Embedded Vision, Kommunikationstechnik und Regelungstechnik von Motoren und Leistungselektronik.
Entwurfteam aus Algorithmus-Ingenieuren und Embedded-Ingenieuren
Die Entwurfsteams setzen sich in der Regel zusammen aus Algorithmus-Ingenieuren, die für die Konzeptentwicklung und Ausarbeitung mathematik- und regelbasierter Algorithmen verantwortlich sind, und Embedded-Ingenieuren, die für die Verfeinerung der Algorithmen und deren Implementierung in Software oder Hardware zuständig sind.
Algorithmus-Ingenieure nutzen die Modellierung bereits frühzeitig im Entwicklungsprozess, um sicherzustellen, dass ihre Algorithmen für die jeweilige Anwendung korrekt funktionieren. Embedded-Ingenieure andererseits erkennen nicht immer sofort die Vorteile der Modellierung. Falls diese Teams jedoch nicht eng zusammenarbeiten, kann es zu einer verspäteten Fehlererkennung und dadurch zu Projektverzögerungen, übermässigem Ressourcenverbrauch oder einer beeinträchtigten Funktionalität aufgrund unzureichender Entwurfs- und Testiterationen kommen.
Vorteil: funktionales Verhalten auf Implementierungsressourcen abstimmen
Der modellbasierte Entwurf kann Algorithmus- und Embedded-Ingenieuren helfen, einen effizienten und kooperativen Entwurfsprozess zu schaffen. Die Konzentration auf Modellierung und Simulation unterstützt frühe Partitionierungsentscheidungen für Algorithmus-Komponenten, Simulation und Codegenerierung und erlauben das funktionale Verhalten auf die Implementierungsressourcen abzustimmen. Die Bereitstellung und Integration von generierten und manuell erzeugten Codes in einem automatisierten Workflow erlaubt es, die Laborzeit für die Prototypenverifikation effizienter zu nutzen.
Der folgende Workflow hat sich bewährt
Für die Implementierung auf SoCs hat sich ein Workflow bewährt, der aus einer Kombination von aus Modellen generiertem Code und manuell bereitgestelltem Code besteht. Der manuell programmierte Code wird hierbei als Referenzdesign bezeichnet. Vom Algorithmus-Entwickler werden Modelle zur Verfügung gestellt, die durch iteratives Hinzufügen von Implementierungsdetails weiter ausgearbeitet werden. Mit jeder Iteration wird das Systemverhalten erneut simuliert, um die korrekte Funktion der Modelle, sowie des aus den Modellen generierten Codes zu gewährleisten. Dieser wird in einem automatisierten Schritt mit dem Referenzdesign integriert und in einem wiederholbaren Prozess zur Hardware-Implementierung weiterentwickelt (Abbildung 1).

Auswahl einer Hardware-Plattform
Für eine Fallstudie soll der Entwurf eines Geschwindigkeitsreglers für einen Permanentmagnet-Synchronmotor unter Verwendung eines feldorientierten Regelalgorithmus (Field-Oriented Control, FOC) betrachtet werden, der auf einen Zynq-7000 All Programmable SoC Intelligent Drives Kit II (Abbildung 2) implementiert wird. Die Motorregelung wurde ausgewählt, da bei dieser Anwendung Algorithmus- und Embedded-Ingenieure eng zusammenarbeiten müssen. Das Zynq Intelligent Drives Kit II wurde gewählt, weil es sofort verfügbar ist und die erforderliche I/O-Schnittstellen-Unterstützung bietet.

Das Zynq Intelligent Drives Kit II ist …
Das Zynq Intelligent Drives Kit II ist eine Entwicklungsplattform, die von Ingenieuren eingesetzt wird, die Motorregelungsalgorithmen auf einem Zynq Z-7020 SoC-Baustein ausführen und testen. Das Kit basiert auf dem ZedBoard-Entwicklungs-Board und umfasst ein Analog Devices FMC-Motorsteuerungsmodul sowie einen bürstenlosen 24-V-Gleichstrommotor mit einem Encoder für 1250 Zyklen/Umdrehung. Da die Motorregelungsalgorithmen unter verschiedenen Betriebsbedingungen getest werden sollen, wird das Zynq Intelligent Drives Kit II mit einem optionalen Dynamometersystem verwendet.
Partitionierung der Algorithmuskomponenten
Ein vom Algorithmus-Ingenieur bereitgestelltes erstes Systemsimulationsmodell muss um weitere Komponenten ergänzt werden, die für die Bereitstellung auf der SoC-Prototypenplattform erforderlich sind. Das Modell umfasst einen Regelalgorithmus für ein auf Datenblattparametern basiertes Motormodell. Der Regelalgorithmus besteht aus einer äusseren Geschwindigkeitsregelschleife, die eine innere Stromregelschleife mithilfe von FOC regelt.
Obgleich dieses Modell den Algorithmus der Regelung erfasst, berücksichtigt es nicht die Auswirkungen der Peripheriekomponenten (wie ADC, Encoder und PWM) oder die für andere Betriebsarten erforderlichen Algorithmuskomponenten (deaktiviert, offene Regelschleife und Encoder-Kalibrierung). Zusammen mit dem Algorithmus-Ingenieur wird ermittelt, welche Komponenten modelliert werden sollen, und ob diese auf dem ARM oder in der programmierbaren Logik im SoC (Abbildung 3) implementiert werden sollen.
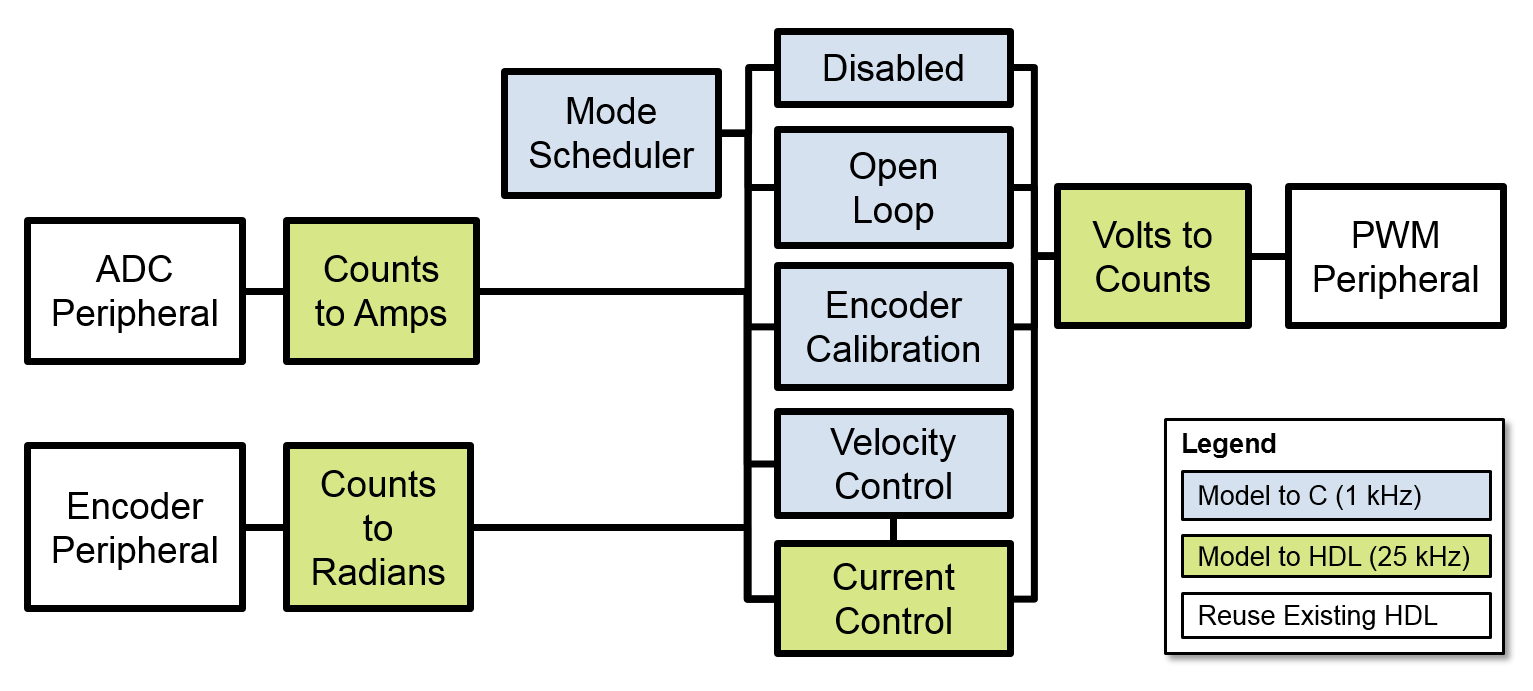
Ursprüngliches Modell mit neuen Algorithmuskomponenten ergänzen
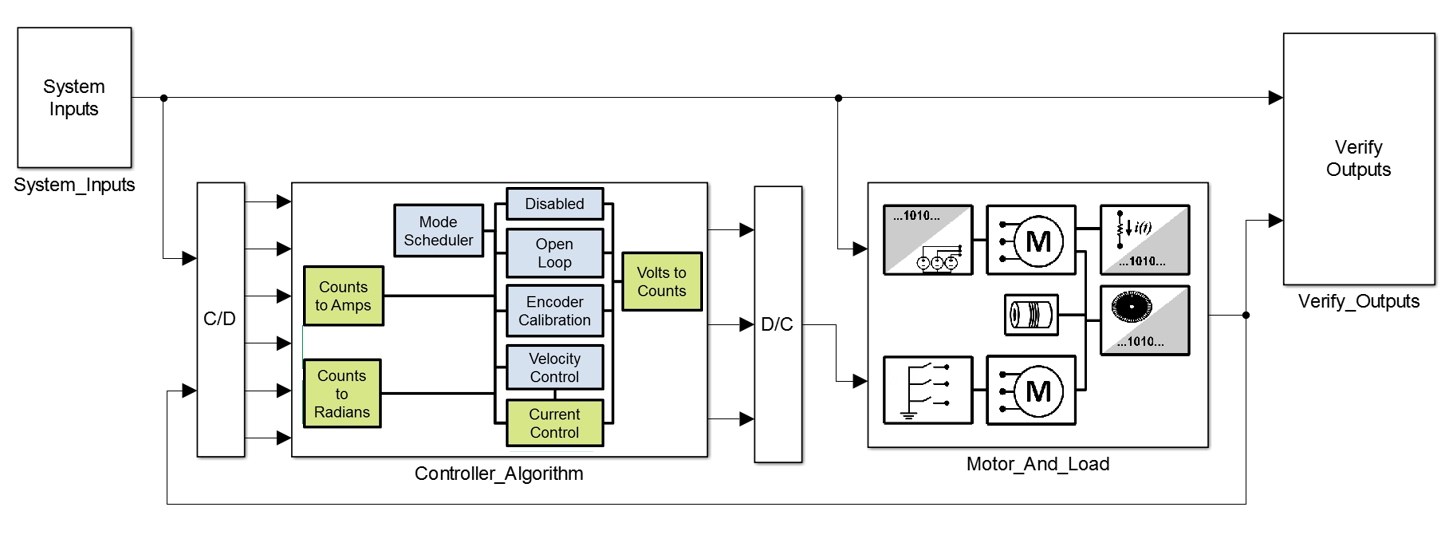
Das ursprüngliche Modell wird mit den neuen Algorithmuskomponenten ergänzt (Abbildung 4). Um die Systemsimulation zu ermöglichen, werden konzentrierte Parametermodelle bestehender Peripheriekomponenten erstellt, die mit dem Motormodell interagieren. Bestehender HDL-Code für z.B. die Peripheriekomponente Encoder, wird im bereitgestellten Entwurf wiederverwendet. Der Encoder liest einen Datenstrom digitaler Impulse bei 50 MHz und übersetzt diese in Zählersignale, die vom Regelungsalgorithmus mit 25 kHz gelesen werden.
Konzentriertes Parametermodell des Encoders erstellen
Eine direkte Modellierung dieses Impulsstroms würde eine 50-MHz-Dynamik in das Systemmodell einführen und die Simulationszeit beträchtlich erhöhen. Stattdessen wird ein konzentriertes Parametermodell des Encoders erstellt, das die ideale Rotorposition aus dem Motormodell in das Encoder-Zählersignal umwandelt, das von den Algorithmuskomponenten verarbeitet wird. Modellierung auf dieser Genauigkeitsstufe ermöglicht die Simulation der zum Testen der Encoder-Kalibrierungskomponente erforderlichen Startbedingungen, sowie die Einführung von Positions-Quantisierungseffekten zum Testen der Geschwindigkeitsregelungs-Komponente (Abbildung 5) bei gleichzeitiger Wahrung angemessener Simulationszeiten.

Algorithmuskomponenten auf dem ARM implementieren
Algorithmuskomponenten mit Raten von einigen kHz oder weniger können auf dem ARM implementiert werden. Die Beschränkung auf Raten mit nur wenigen kHz wird von dem Linux-Betriebssystem vorgegeben, das auf dem ARM ausgeführt werden soll. Algorithmuskomponenten, die schnellere Raten erfordern, sollen im FPGA implementiert werden.
Wenn möglich, sollen Algorithmuskomponenten bevorzugt auf dem ARM implementiert werden, da Entwurfs-Iterationen auf dem ARM schneller als auf dem FPGA durchgeführt werden können. Es ist auch einfacher, den Algorithmus auf den ARM-Prozessorkern zu implementieren, weil er native mathematische Gleitkomma-Operationen unterstützt. Die meisten FPGAs führen Gleitkomma-Operationen nur ineffizient aus, daher erfordert die Implementierung in programmierbarer Logik den zusätzlichen Schritt der Umwandlung von Algorithmen in das Festkommaformat. Darüber hinaus ist der Prozess der Kompilierung von C-Code für den ARM in der Regel deutlich schneller als der zum Kompilieren von HDL-Code für das FPGA.
Langsam genug für den ARM? Oder doch FPGA?
Die Simulation kann dazu verwendet werden, zu bestimmen, ob einzelne Algorithmuskomponenten bei Raten ausgeführt werden können, die langsam genug für den ARM sind oder ob das FPGA erforderlich sein wird. Ein Beispiel: Der Algorithmus-Ingenieur schlägt zunächst eine Encoder-Kalibrierungsroutine vor, die bei 25 kHz ausgeführt und auf dem FPGA implementiert werden soll. Die Simulation bietet die Möglichkeit einer Untersuchung der Encoder-Kalibrierungskomponente bei 1 kHz und die Ergebnisse zeigen, dass auch eine Implementierung auf dem ARM-Kern möglich ist.
Nach der Entwicklung der funktional korrekten Modelle mit den gewünschten Taktraten, können die für die C-Codegenerierung vorgesehenen Komponenten in einem Algorithmus-C-Modell gruppiert werden und alle Komponenten für die HDL-Codegenerierung in einem Algorithmus-HDL-Modell (Abbildung 6). Anschliessend werden iterativ Implementierungsdetails zu den Modellen hinzugefügt und Code generiert, bis der generierte C-Code in einen akzeptablen Speicherbereich passt und mit der Komponentenrate ausgeführt werden kann.

Aus Algorithmus-C-Modell C-Code generieren und Bericht erstellen
Mit Hilfe von Embedded Coder kann aus dem Algorithmus-C-Modell C-Code generiert und ein Bericht erstellt werden, in dem die Schnittstelle des Aufrufs sowie die geschätzte Datenspeichernutzung zusammengefasst sind. In einem ersten Schritt sind alle Datentypen Gleitkommazahlen doppelter Genauigkeit. Für die Daten, die eine Schnittstelle mit dem FPGA bilden, sollen jedoch Ganzzahl- oder Festkomma-Datentypen verwendet werden. Der Rest der Mathematik soll vom Datentyp Gleitkommazahl einfacher Genauigkeit sein. Nach Anwendung dieser Datentypen auf das Modell wird mittels Simulation bestätigt, dass das Verhalten noch akzeptabel ist und daraufhin ein optimierter Code generiert. Zu diesem Zeitpunkt kann man bereits einschätzen, dass der Code für die Implementierung auf dem ARM geeignet ist.
Das Algorithmus-HDL-Modell wird mit Festkomma-Datentypen implementiert, da Festkomma-Operationen auf FPGAs weniger Ressourcen verbrauchen. Dazu kann mit dem Algorithmus-Ingenieur zusammengearbeitet werden, um die Wertebereiche von Schlüsselsignalen im Entwurf zu identifizieren und festzuhalten (z.B. Stromstärke, Spannung und Geschwindigkeit). Daraufhin werden mithilfe von Fixed-Point-Designer Festkomma-Datentypen definiert, die gewährleisten, dass es zu keinem Berechnungsüberlauf kommt. Mithilfe von HDL Coder werden der HDL-Code und ein Code-Generierungsbericht erstellt.
Mathematische Operationen identifizieren, die unerwartet umfassend erscheinen
Der Abschnitt des Berichts über die Ressourcennutzung kann verwendet werden, um mathematische Operationen zu identifizieren, die unerwartet umfassend erscheinen. In diesem Fallbeispiel kann eine anfängliche Auswahl der Wortlängen zu mehreren Multiplikationen von zwei 34-Bit-Zahlen führen, was unnötig FPGA-Ressourcen aufbrauchen würde. Dieses Problem kann im Ressourcennutzungsbericht identifiziert, die Präzision im Modell reduziert und mithilfe der Simulation bestätigt werden, dass die Funktionalität noch korrekt ist. Daraufhin kann der optimierte HDL-Code generiert und mithilfe von Xilinx Vivado Design Suite synthetisiert werden. Die anschliessende statische Timing-Analyse bestätigt die Einhaltung der Zeitanforderungen im FPGA.
Nachdem ein erster Kandidat für die Implementierung des Algorithmus vorbereitet wurde, kann er in das Referenzdesign integriert werden. Im ersten Durchlauf wird eine manuelle Integration der generierten C-Funktionalität mithilfe des manuell codierten Embedded-ARM-Projekts und der Integration der generierten HDL-Entity in das manuell codiertes Vivado-Projekt durchgeführt.
Bei dieser manuellen Vorgehensweise wäre es erforderlich, dass die Embedded-Ingenieure für die Integration jeder Entwurfsiteration verfügbar sind. Ein Ziel bei der Verwendung des vorgestellten Workflows bestand darin, ihn weitgehend zu automatisieren und somit den Algorithmus-Ingenieur in die Lage zu versetzen, den Integrations- und Bereitstellungsprozess im Labor selbständig durchzuführen.
Das HDL Coder Support Package verwenden
Dazu kann das HDL Coder Support Package für die Xilinx Zynq-Plattform verwendet werden, um das manuell codiertes Vivado-Projekt als Referenzdesign zu registrieren. Somit kann die Integration des generierten Algorithmus-HDL-Codes mit dem manuellen Code automatisiert, einen Bitstream erstellt und auf das FPGA herunterladen werden. Mit Hilfe des Embedded Coder Support Package für die Xilinx Zynq-Plattform kann die Automatisierung der Integration des generierten Algorithmus-C-Codes mit einem Linux-Betriebssystem, die Erstellung einer ausführbaren Datei, das Herunterladen dieser Datei auf den ARM-Prozessor und die Interaktion mit dem ausgeführten Programm über Simulink erfolgen. Die Support-Pakete stellten das AXI-Interconnect bereit, das die Kommunikation zwischen den Algorithmuskomponenten im ARM-Prozessorkern und der programmierbaren Logik ermöglicht.
Algorithmus- und Embedded-Ingenieure arbeiten im Labor eng zusammen
Während der anfänglichen Systemeinrichtung ist es notwendig, dass Algorithmus- und Embedded-Ingenieure im Labor eng zusammenarbeiteten. Die Embedded-Ingenieure müssen die Deployment-Konfiguration einrichten und mit dem Algorithmus-Ingenieur zusammenarbeiten, um die grundlegende Funktionalität zu verifizieren. Nachdem das System eingerichtet ist, kann der Algorithmus-Ingenieur selbstständig Entwurfsiterationen ausführen und über Simulink mit dem SoC kommunizieren.
Der Algorithmus-Ingenieur testet die eingesetzte Regelung und verifiziert die Ergebnisse. Der Vergleich der Simulations- und Hardware-Ergebnisse kann in diesem Fallbeispiel darauf hinweisen, dass die Zuordnung des ADC-Zählerwertes zur Stromstärke falsch berechnet wurde. Daraufhin kann der Algorithmus-Ingenieur weitere Tests erstellen, um die Drehmomentkonstante des Motors besser zu charakterisieren und die Korrelation zwischen Simulation und Hardware (Abbildung 7) zu verbessern.

Die hohe Korrelation zwischen den Simulations- und Hardware-Testergebnissen zeigt, dass sinnvolle Entwurfsentscheidungen auf Modellebene getroffen und die Laborzeit durch den intergrierten Workflow weiter reduziert werden kann.
Vorteile dieses Ansatzes
Der hier beschriebene Workflow ermöglicht eine effizientere Zusammenarbeit zwischen Emedded-Ingenieuren und Algorithmus-Ingenieuren als zuvor. Durch Simulation können die Auswirkung der Algorithmus-Partitionierung auf die Systemleistung beurteilt und verifiziert werden, z.B. dass die Encoder-Kalibrierungskomponente von der höherratigen programmierbaren Logikpartition zur niederratigen ARM-Partition verschoben werden konnte.
Die Simulation ermöglicht es auch, Entscheidungen zu treffen, die Implementierungsressourcen einsparen, während gleichzeitig das funktionale Verhalten erhalten bleibt. Hierzu gehört z. B. die Reduzierung der Wortlänge mathematischer Operationen in der programmierbaren Logik oder die Konvertierung der über das AXI-Interconnect weitergeleiteten Daten von Gleitkomma- in Festkomma-Datentypen. Schliesslich ermöglichen Prototypentests im Labor es den Algorithmus-Ingenieuren weitere Tests zur Charakterisierung der Drehmomentkonstante des Motors durchführen.
Insgesamt unterstützt der Workflow eine enge Zusammenarbeit zwischen Embedded- und Algorithmus-Ingenieuren, wodurch eine effizientere Implementierung ermöglicht und gleichzeitig Laborzeit eingespart werden kann.

Impressum
Autor: Dr.-Ing. Werner Bachhuber, Mathworks
Bildquelle: Mathworks
Publiziert von Technik und Wissen
Informationen
Mathworks
mathworks.com



Veröffentlicht am: